Data Structure and Serialization¶
TBone provides an ODM (Object Document Mapper) for declaring, validating and serializing data structures.
Note
Data structure and data persistency are decoupled in TBone.
The ODM is implemented seperately from the persistency layer and thus allows for implementing other datastore persistency layers, in addition to the default one for MongoDB
The Model class is used as the Base for all data models, with an optional DB mixin class for persistency.
Define a Schema¶
The ODM works very similarly to Django models or other ORMS and ODMs for Python. The main difference is that the classes are not bound, by default, to a datastore.
For more information on binding a model to a datastore see Persistency
Models¶
Defining a model is done like so:
from tbone.data import Model
class Book(Model):
title = StringField(required=True)
publication_date = DateField()
authors = ListField(StringField)
number_of_pages = IntegerField()
Each field in the model is defined by its matching type and by optional parameters which affect its validation and serialization behavior.
Note
Why is TBone not using an external Python schema and validation library such as Marshmallow or Schematics ?
Both libraries mentioned above are excellent for performing the tasks of schema definition, data validation and serialization. However, both libraries were developed to be generic and do not use the asynchronous capabilities of TBone to their advantage. Therefore TBone implements its own data modeling capabilities which are designed to work in an asynchronous nonblocking environment. An example of this is explained in detail in the Serialize Methods section
Fields¶
Fields are used to describe individual variables in a model schema. There are simple fields for data primitives such as int and str and there are composite fields for describing data such as lists and dictionaries.
Developers who have a background in ORM implementations such as the one included in Django, should be very familiar with this concept.
All fields classes derive from BaseField and implement coersion methods to and from Python natives, with respect to their designated data types.
In addition, fields provide additional attributes pertaining to the way data is validated, and the way data is serialized and deserialized. They also provide additional attributes for database mixins
Attributes¶
The following table lists the different attributes of fields and how they are used
| Attribute | Usage | Default |
|---|---|---|
required |
Determines if the field is required when data is imported or deserialized | False |
default |
Declares a default value when none is provided. May be a callable | None |
choices |
Set a list of choices, limiting the field’s acceptable values | None |
validators |
A list of callables to provide external validation methods. See validators | None |
projection |
Determines how the field’s data is serialized. See Projection | True |
readonly |
Determines if data can be deserialized into this field. See Deserialization | False |
primary_key |
Used by resources to determine how to construct a resource URI | False |
There are additional attributes which pertain only to specific fields. For example, min and max can be defined for an IntegerField to determine a range of acceptable values. See the API Reference for more details.
Composite Fields¶
Composite fields are used to declare lists and dictionaries using the ListField and DictField fields respectively. A composite field is always based on another field which acts as the base type.
A list of integers will be defined as ListField(IntegerField) and a dictionary of strings will be defined as DictField(StringField) .
The base field which defines the composite field can also accept the standard field attributes. The composite field itself can also define attributes related to its own behavior, like so:
class M(Model):
counters = DictField(IntegerField(default=0))
tags = ListField(StringField(default='Unknown'), min_size=1, max_size=10)
Nested Models¶
Documents can contain nested objects within them. In order to declare a nested object within your model, simply define the nested object as a model class and use the ModelField to associate it with your root Model, like so:
class Person(Model):
first_name = StringField()
last_name = StringField()
class Book(Model):
title = StringField(required=True)
publication_date = DateField()
author = ModelField(Person)
This data model will produce an output like this:
{
"title": "Mody Dick",
"publication_date" : "1851-10-18",
"author" : {
"first_name" : "Herman",
"last_name" : "Melville"
}
}
Nested objects can also be as the base fields for within lists and dictionaries, like so:
class Book(Model):
title = StringField(required=True)
publication_date = DateField()
authors = ListModel(ModelField(Person))
This data model will produce an output like this:
{
"title": "The Talisman",
"publication_date" : "1984-11-08",
"authors" : [{
"first_name" : "Stephen",
"last_name" : "King"
},{
"first_name" : "Peter",
"last_name" : "Straub"
}]
}
Note
If you are using a data persistency mixin such as the MongoCollectionMixin you should only add the mixin to your root model and not to any of your nested models.
Model Options¶
Every Model derived class has an internal Meta class which defines its default parameters. This is a very similar approach to meta information declared in Django models.
The following table lists the model options defined within the Meta class.
| Option | Usage | Default |
|---|---|---|
name |
Name of the model.
This is used in persistency mixins to
set the name in the datastores
|
name of
the model
|
namespace |
Declares a namespace which prepends the name of the Model | None |
exclude_fields |
Exclude fields from base models in subclass | [] |
exclude_serialize |
Exclude serialize methos from base model in subclass | [] |
creation_args |
Used by
MongoCollectionMixinfor passing creation arguments
|
None |
indices |
Used to declare database indices | None |
Excluding fields and serialize methods¶
The Model’s Meta class includes two lists for removing fields and serialize methods inherited from the base class.
This is useful when wanting to create multiple resources for the same model, which expose a different set of fields.
Consider the following example:
class User(Model):
username = StringField()
password = StringField()
first_name = StringField()
last_name = StringField()
@serialize
async def full_name(self):
return '{} {}'.format(self.first_name, self.last_name)
class PublicUser(User):
class Meta:
exclude_fields = ['password']
exclude_serialize = ['full_name']
In this example demonstrates how create a User model, and a PublicUser model, which is a variation of the User model, by inheriting User and then omitting the password field and the full_name serialize method.
Data Traffic¶
Models are iterim data components that hold data in memory, coming in and out of the application. Generally, data travels from and to datastores and and application consumers. Models hold the data in memory and facilitate data management in the application flow.
The Model class is a central part of TBone and has two data traffic concepts:
- Import and Export
- Serialization and deserialization
The big difference between the two data traffic concepts is their purpose. Import and export take data in and out of the Model exactly as it is defined in the schema. Serialization and deserialization provides mechanisms for developers to control how data flows in and out of the Model to suit the application logic.
Generally speaking, import and export are used for data storage while serialization and deserialization are used for API resources and buiness logic.
The following diagram illustrates this:
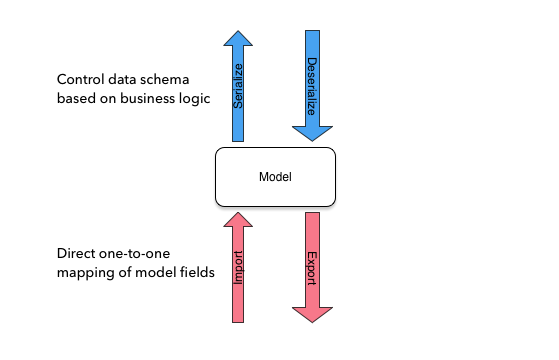
It may be useful to consider import / export methods as inbound methods, used for storing data in datastores and serialization / deserialization methods as outbound methods, used for exposing APIs in a controlled manner
Import Data¶
There are multiple ways to manipulate data on a Model.
The most obvious is to access it’s fields directly, like so:
>>> book = Book()
>>> b.title = 'Crime and Punishment'
While this example is pretty straighforward, it may not be very efficient if in cases were data is already stored in a dict which needs to be imported into a Model.
The import_data method takes care of that, like so:
>>> data = {
... 'title': 'Crime and Punishment',
... 'author': ' Fyodor Dostoyevsky',
... 'publication_date': '1866-01-01' # actual date varies
... }
>>>
>>> book = Book()
>>> book.import_data(data)
A quicker way would be to use the Model constructor, like so:
>> book = Book(data)
Data can be imported in a dict containing Python types, or data primitives. Once data is imported into the model is coerced into Python types and validated.
Export Data¶
The export_data method is used to convert the model into a Python dict.
The data is exported in a straighforward manner, mapping all Model fields to key/value pairs, like so:
>>> data = book.export_data()
>>> data
{'isbn': '9781602523692', 'title': 'War and Peace', 'author': ['Leo Tolstoy'], 'format': 'Paperback', 'publication_date': datetime.datetime(1869, 1, 1, 0, 0, tzinfo=tzutc()), 'reviews': [], 'number_of_impressions': 0, 'number_of_views': 0}
>>> type(data)
<class 'dict'>
The export_data method exports all data in native Python types. It accepts an optional native parameter to control how data is exported. If native is set to False data will be exported in primitive data types, like so:
>>> data = book.export_data(native=False)
>>> data
{'isbn': '9781602523692', 'title': 'War and Peace', 'author': ['Leo Tolstoy'], 'format': 'Paperback', 'publication_date': '1869-01-01T00:00:00+00:00', 'reviews': [], 'number_of_impressions': 0, 'number_of_views': 0}
>>> type(data)
<class 'dict'>
Observing the difference with the previous example where publication_date was exported native python datetime in this example publication_date was exported as a ISO_8601 formatted string.
Validation¶
Model validation is the process of validating the data contained by the model. Validation is done individually for every field in the Model, and can also include model level validation, to combine values of multiple fields. When
Model.validatethe model iterates through all its fields and call their respectivevalidatemethods individually. Each type of field implements its own validation, pertaining to its data type.Explicitly calling the model validation is done like so:
m = MyModel({'name': 'ron bugrundy'}) m.validate()
The Model.validate method does not return any value. However, a ValueError exception will be thrown if any validation has failed.
There are 3 forms of field validation:
- Type validation - Coercing the assigned data to the field’s data type.
- Validator methods - These are field methods which are decorated with
@validatorand perform additional validation that requires logic- External validator functions - These are functions which are external to the field class and are passed into field’s declaration
To add an external validation to an existing field object, without subclassing, is done like so:
def validate_positive(value):
if value < 0:
raise ValueError('Value should be positive')
class Person(Model):
age = IntegerField(validators=[validate_positive])
In this example an external validation method was added to the list of validators without subclassing IntegerField.
This approach is useful when sharing validation methods across different fields.
Another approach is to subclass IntegerField and include the validation within the field it self, like so:
class PositiveIntegerField(IntegerField):
@validator
def positive(value):
if value < 0:
raise ValueError('Value should be positive')
In this example the validation is implemented within the field’s subclass.
Serialization¶
Models are responsible not only for declaring a schema and validating the data, but also for serializing the models to useful data structures. Controlling the way data models are serialized is extremely useful when creating APIs. More often than not, the application’s requirements dictate cases other than a straightforward one-to-one mapping between the data attributes of a model and the API. In some cases there may be a need to omit some data, which is meant only for internal use and not for API consumption. In other cases there may be additional data attributes, required as part of an API endpoint, which are a result of a calculation, aggregation, or data manipulation between 1 or more data attributes.
The following section reviews the tools that are implemented on the Model class and how they can be used to yield the desired results.
Model serialization is done using the serialize method:
This will produce a Python dict with the model’s data. Unlike the export_data method, the one-to-one mapping of data fields is the default behavior. Developers can use Projection and the @serialize decorator to control the serialization of the model
Note
Model.serialize is a coroutine, which needs to be awaited, or pushed into the event loop
Projection¶
The previous section went over Model serialization methods. This section covers specific instructions that can be added to the Field in order to determine how it is serialized.
Every Field in the Model has a projection attribute, which defaults to True.
The projection field is a ternary value which can be set to either True, False or None and determines the field’s serialization in the following way:
Truemeans that theFieldwill always be serialized, even if its value isNoneFalsemeans that theFieldwill only be serialized if its value is notNoneand will be skipped otherwise.Nonemeans that theFieldwill never be serialized, regardless of its value.
When a Model serialization method is called, it iterates through all the fields and uses the projection attribute to determine if and how to serialize the specific field.
The following example illustrates this:
>>> from tbone.data.models import *
>>> from tbone.data.fields import *
>>> class BlogPost(Model):
... title = StringField()
... body = StringField()
... number_of_views = IntegerField(default=0, projection=None)
...
>>> post = BlogPost({'title': 'Trees Are Tall', 'body': 'Trees can grow to be very tall ...'})
>>> await post.serialize()
{'title': 'Trees Are Tall', 'body': 'Trees can grow to be very tall ...'}
Note
Plain Python shell await a co-routines as it does not have a running event loop. You can either script this code wrapped as a co-routine or use a 3rd party Python shell which supports an event loop.
The above example illustrates a Model that has a field used, in this case, for analytics, and is not required to be included as part of the API
serialize methods¶
When designing APIs, it is sometimes required to expose data which is not directly mapped to a single field in the model’s schema.
Such data can be a result on a calculation, data aggregation or even data fetched from sources outside the model.
For this purpose, the Model class can implement serialize methods.
Serialize methods are regular member methods on the model with the following attributes:
- Serialize methods accept no external parameters and rely only on the model’s data
- Serialize methods always return a primitive value
- Serialize methods are decorated with the
@serializedecorator- Serialize methods are coroutines and therefore are prefixed with
async
The following example illustrates this:
>>> from tbone.data.models import *
>>> from tbone.data.fields import *
>>> class Trainee(Model):
... weight = FloatField()
... height = FloatField()
... @serialize
... async def bmi(self): # body mass index
... return (self.weight*703)/(self.height*self.height)
...
>>> t = Trainee({'weight': 81.5, 'height' : 178})
>>> t.serialize()
{'weight': 81.5, 'height': 178.0, 'bmi': 1.8083101881075623}
(Please do not consider the above example to be a real BMI calculator)
The example above brings the quetion of why serialize methods need to be coroutines.
In the bmi serialize example there are no lines of code which make use of the application’s event loop.
However, serialize functions may include data from external sources as well. If such an implementation would not be using a coroutine the code will be blocking.
The following example illustrates this:
from aiohttp import client
from tbone.data.models import Model
from tbone.data.fields import *
API_KEY = '<get your own for free>';
QUERY_URL = 'http://api.openweathermap.org/data/2.5/forecast?appid={key}&q={city},{state}'
class CityInfo(Model):
city = StringField()
state = StringField()
@serialize
async def current_weather(self):
async with aiohttp.ClientSession() as session:
async with session.get(QUERY_URL.format(key=API_KEY, city=self.city, state=self.state)) as resp:
if resp.status == 200: # http OK
data = await resp.json()
return data['list'][0]['main']['temp']
return None
.
.
.
city_info = CityInfo({'city': 'San Francisco', 'state': 'CA'})
serialized_data = await city_info.serialize()
To see a fully working example, please visit the examples page in the project’s repository
De-serialization¶
De-serialization is the process of constructing a data model from raw data, usually passed into the API.
The Model class implements a deserialize method which, by default, matches the data being passed to the fields defined on the model. Variables are assigned to their respective fields and the object’s data is validated.
Developers may want to customize this behavior to control how models are deserialized, from data.
Readonly¶
Every model field can be assigned with the readonly attribute.
This tells the model never to accept incoming data to certain fields using the deserialization method.
The following example illustrates this:
class User(Model):
username = StringField(required=True)
password = StringField(readonly=True)